
مدلهای زبان بزرگ یا Large Language Models چیست؟
هوش مصنوعی به عنوان یک حوزه علمی چندرشتهای همواره در حال توسعه روشها و الگوریتمهایی است که به رایانهها توانایی پردازش و فهم زبان طبیعی انسان را میدهد. یکی از دستاوردهای بزرگ در این زمینه، پیدایش مدلهای زبانی بزرگ است که قدرت تجزیه و تحلیل متون را بهبود بخشیدهاند. این مدلها، نوعی از مدلهای ماشینی پیشرفته در حوزه پردازش زبان طبیعی هستند که با استفاده از شبکههای عصبی پیچیده، توانایی درک و تولید متون انسانی را دارند. این مدلها با استفاده از تعداد زیادی پارامتر و مجموعه دادههای عظیم آموزش داده میشوند و میتوانند در مواجهه با متون جدید، محتوای مناسب تولید و پاسخهای هوشمندانه ارائه دهند.

ویژگیهای اصلی مدل زبانی بزرگ
مدلهای زبانی بزرگ برای عملکرد خود از عناصر و فرآیندهای گوناگونی استفاده میکنند. به عنوان مثال، شبکههای عصبی عمیق یکی از عناصر کلیدی در ساختار این مدلها هستند. این شبکهها با دارا بودن لایههای متعدد و مسیرهای انتقالی، اطلاعات زبانی را تجمیع و پردازش میکنند. همچنین، مدلهای زبانی بزرگ از یادگیری انتقالی بهره میگیرند؛ به این صورت که ابتدا با استفاده از متون حجیم آموزش داده میشوند و سپس این دانش به مدلهای کوچکتر از طریق وزندهی به کلمات و جملات منتقل میشود.
آیا مدلهای زبانی بزرگ قابلیت بهبود خود را دارند؟
یکی از ویژگیهای مهم مدلهای زبانی بزرگ، پیشآموزش خودنظارتی است. در این روش، هوش مصنوعی بدون نیاز به برچسبگذاری (تگ)، متون ورودی را به طور کامل پردازش کرده و تلاش میکند الگوها و ارتباطات زبانی را در آنها شناسایی کند. علاوه بر این، مدلهای زبانی بزرگ دارای تعداد زیادی پارامتر هستند که نمایانگر وزنهایی است که برای هر نورون در شبکههای عصبی تنظیم میشوند. فراوانی این پارامترها به مدل کمک میکند تا دانش زبانی گستردهای را نگهداری و استفاده کند.

کاربردهای مد لهای زبانی بزرگ
مدلهای زبانی بزرگ یا Large Language Models امروزه کاربردهای گستردهای پیدا کردهاند و در زمینههای مختلفی مانند ترجمه ماشینی، تولید محتوای خودکار، تشخیص احساسات متون، پاسخگویی به سوالات، تفسیر متون، پشتیبانی مشتریان و دیگر زمینهها در حوزه هوش مصنوعی و پردازش زبان طبیعی استفاده میشوند. مدلهای زبانی بزرگ تواناییهای گستردهای در پردازش زبان طبیعی دارند و میتوانند انواع عملیاتهای مختلف را انجام دهند. در ادامه به برخی از این کاربردها اشاره میشود:
- ترجمه ماشینی: یکی از کاربردهای مهم مدلهای زبانی بزرگ، ترجمه ماشینی است. این مدلها با تشخیص الگوها و ساختارهای زبانی در متون، میتوانند متون را از یک زبان به زبان دیگر ترجمه کنند که امروزه بسیاری از مردم جهان از آن بهره میگیرند.
- تولید متن خودکار: مدلهای زبانی بزرگ قادر به تولید متون خودکار با موضوعات مشخص هستند که از آن برای نگارش مقالات، محتواهای اینترنتی و حتی داستانها استفاده میشود.
- پاسخگویی به سوالات: مدلهای زبان بزرگ میتوانند به سوالات کاربران پاسخهای منطقی و متناسب بدهند که در مواردی کیفیت و دقت پاسخهای داده شده بسیار شگفتانگیز است.
- تشخیص احساسات: این مدلها قادرند احساسات موجود در متون را شناسایی کرده و درک کنند. این ویژگی در تجزیه و تحلیل نظرات مشتریان و تفسیر متون بسیار مهم است.
- خلاصهسازی متون: مدلهای زبانی بزرگ میتوانند متون طولانی را به خلاصههای کوتاهتر تبدیل کنند. این کاربرد معمولاً برای خلاصهسازی مقالات یا متون طولانی استفاده میشود.
- پشتیبانی مشتریان: این مدلها توانایی پاسخگویی خودکار به سوالات و درخواستهای مشتریان را دارند که در بهبود تجربه مشتری در ارتباط با شرکتها بسیار مؤثر است.
- تولید گفتگوهای دوطرفه طبیعی: مدلهای زبانی بزرگ قادر به ایجاد مکالمات و دیالوگهای طبیعی با انسانها هستند. این ویژگی در برنامههای چت بات مورد استفاده قرار میگیرد و امروزه نمونههای متعددی از آن به شکل رایگان در دسترس است.
موارد فوق تنها چند نمونه از قابلیتهایی هستند که مدلهای زبانی بزرگ در حوزه پردازش زبان طبیعی و هوش مصنوعی میتوانند انجام دهند. این مدلها با توانمندیهای خود در ایجاد خروجیهای متنی هوشمندانه، برای بسیاری از شرایط قابل استفاده هستند.

سوالات متداول در مورد مدلهای زبانی بزرگ:
آیا برای استفاده از مدلهای زبانی بزرگ (LLM) باید به اینترنت دسترسی داشته باشم یا میتوانم آنها را روی زیرساخت سختافزاری سازمان/شرکت خود نصب کنم؟
شما میتوانید هر دو کار را انجام دهید. برخی از مدلهای زبانی بزرگ، به ویژه آنهایی که توسط سرویسهای ابری (cloud services) ارائه میشوند، نیاز به دسترسی به اینترنت دارند. با این حال، مدلهایی نیز وجود دارند که میتوان آنها را خریداری کرده و روی سختافزار محلی خود اجرا کنید. اجرای مدلهای زبانی بزرگ به صورت محلی نیازمند منابع محاسباتی قابل توجهی است که بستگی به اندازه و پیچیدگی مدل دارد.
شرکت/سازمان من ارباب رجوعهای زیادی از جمله مشتریان دارد، فرآیند آموزش تمام دانش داخلی سازمان/شرکت به LLM و ارائه یک چتبات به مشتریان برای پشتیبانی آنها چگونه است؟
این فرآیند شامل چند مرحله کلیدی است:
- جمعآوری داده (Data Collection): جمعآوری تمامی دانش داخلی مربوطه، شامل اسناد، ایمیلها، تعاملات مشتریان، سوالات متداول (FAQs) و غیره.
- پیشپردازش داده (Data Preprocessing): پاکسازی و پیشپردازش دادهها برای آمادهسازی آنها جهت آموزش مدل زبانی بزرگ. این شامل حذف اطلاعات غیرضروری، استانداردسازی فرمتها و اطمینان از کیفیت دادهها میشود.
- آموزش مدل (Model Training): تنظیم دقیق (fine-tuning) یک مدل زبانی بزرگ موجود با دادههای داخلی شما برای آموزش آن به دانش خاص مربوط به شرکت شما.
- یکپارچهسازی چتبات (Chatbot Integration): استقرار مدل زبانی بزرگ تنظیم شده در یک چارچوب چتبات، اطمینان از اینکه میتواند با پلتفرمهای خدمات مشتری شما ارتباط برقرار کند.
- آزمایش و اعتبارسنجی (Testing and Validation): آزمایش چتبات به طور گسترده برای اطمینان از اینکه به درستی مشتریان را درک کرده و به سوالات آنها پاسخ میدهد.
- استقرار و نظارت (Deployment and Monitoring): راهاندازی چتبات برای مشتریان و نظارت مداوم بر عملکرد آن برای انجام تنظیمات لازم.
پارامترهایی که زمان و بودجه پروژه من را تحت تأثیر قرار میدهند کدامند و چگونه میتوان آنها را محاسبه کرد؟
-
اندازه دادههای آموزشی (Size of the Training Data)
دادههای بیشتر نیاز به زمان پردازش و منابع محاسباتی بیشتری دارند. بطور مثال، اگر آموزش 1 ترابایت (1 TB) داده نیاز به 2000 ساعت زمان GPU داشته باشد و هر ساعت GPU هزینهای معادل $2 داشته باشد، هزینه به این صورت خواهد بود: 2000 ساعت * $2/ساعت = $4000
-
پیچیدگی مدل (Complexity of the Model):
مدلهای زبانی بزرگتر با تعداد پارامترهای بیشتر زمان بیشتری برای آموزش نیاز دارند و به سختافزار قدرتمندتری نیاز دارند. بطور مثال: اگر یک مدل کوچک 1000 ساعت زمان GPU نیاز داشته باشد و یک مدل بزرگتر با 10 برابر تعداد پارامترها 10000 ساعت نیاز داشته باشد: 10000 ساعت * $2/ساعت = $20000
مدلهای معمول دارای 340 میلیون، 1.3 میلیارد، 1.6 میلیارد، 3 میلیارد، 8 میلیارد، 11 میلیارد، 70 میلیارد، 175 میلیارد، 405 میلیارد پارامتر و بیشتر هستند.
-
کیفیت داده (Quality of Data):
دادههای با کیفیت بالا و ساختار یافته میتوانند زمان پیشپردازش (preprocessing) را کاهش داده و کارآیی آموزش را بهبود بخشند.بطور مثال اگر پیشپردازش دادهها 100 ساعت زمان نیاز داشته باشد اما به دلیل کیفیت بالاتر به 70 ساعت کاهش یابد، با نرخ $50/ساعت برای پاکسازی دادهها:
(100 – 70) ساعت * $50/ساعت = $1500 صرفهجویی
-
منابع محاسباتی (Computational Resources):
دسترسی به GPUها یا TPUها میتواند به طور قابل توجهی بر زمان آموزش تأثیر بگذارد.به طور مثال استفاده از 8 عدد GPU با هزینه $2/ساعت برای 2000 ساعت مجموعاً: 8 GPU * 2000 ساعت * $2/ساعت = $32000
-
منابع انسانی (Human Resources):
تخصص تیمی که در آموزش و استقرار مدل درگیر است.به عنوان نمونه: یک تیم از 3 متخصص که هر کدام 200 ساعت با نرخ $50/ساعت کار میکنند: 3 متخصص * 200 ساعت * $50/ساعت = $30000
-
هزینههای زیرساخت (Infrastructure Costs):
اگر بجابی سخت افزار داخلی از خدمات ابری استفاده شود، هزینههای مرتبط با خدمات ابری (cloud services)، سختافزار و مجوزهای نرمافزاری در هزبینه ها موثر است. محاسبه نمونه: خدمات ابری با هزینه $1000/ماه، مجوزهای نرمافزاری با هزینه $500/ماه، استهلاک سختافزار $300/ماه در طول پروژه 6 ماهه: (6 * $1000) + (6 * $500) + (6 * $300) = $10800
چگونه مدلهای زبانی بزرگ (LLMs) میتوانند برای پاسخگویی تنها به برخی سوالات یا مفاهیم محدود شوند؟
مدلهای زبان بزرگ (LLMs) میتوانند برای پاسخگویی تنها به سوالات یا مفاهیم خاص محدود شوند. این کار از طریق چند روش انجام میشود:
- فاین تیونینگ (Fine-Tuning): آموزش مدل بر روی مجموعه دادهای خاص که فقط شامل مفاهیم یا نوع سوالات مورد نظر است. این کار کمک میکند مدل بر روی موضوعات مربوطه تمرکز کند.
- مهندسی پرامپت (Prompt Engineering): طراحی دقیق پرامپتها (prompts) برای هدایت پاسخهای مدل. استفاده از دستورالعملهای واضح و مشخص در پرامپت (prompt) میتواند به هدایت مدل به سمت خروجی مطلوب کمک کند.
- کنترل دسترسی (Access Control): اجرای کنترلهای دسترسی در سطح سیستم که توانایی مدل را برای پاسخگویی به موضوعات یا انواع سوالات خاص محدود کند.
- فیلترهای API (API Filters): استفاده از فیلترها و مراحل اعتبارسنجی در تماسهای API برای اطمینان از اینکه تنها سوالات مرتبط به مدل ارسال میشوند.
- محدودیتهای کلمات کلیدی (Keyword Restrictions): تعریف لیستی از کلمات کلیدی مجاز یا غیرمجاز. مدل میتواند برنامهریزی شود که تنها در صورتی پاسخ دهد که ورودی شامل کلمات کلیدی خاصی باشد.
سختافزار مورد نیاز برای اجرای مدلهای زبانی بزرگ(LLM) درسازمان من چیست؟ چگونه میتوان مصرف سختافزار را محاسبه کرد، چه پارامترهایی بر آن تأثیر میگذارند؟
برای محاسبه مصرف سختافزار میتوانید از فرمول زیر برای برآورد مشخصه های سخت افزاری استفاده کنید:
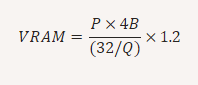
با فرض اینکه:
VRAM = حافظه GPU مورد نیاز (به گیگابایت)
P = تعداد پارامترهای مدل(مثلاً 70 میلیارد برای Llama 70B))
4B= 4 بایت به ازای هر پارامتر
32= 32 بیت در هر 4 بایت
Q = تعداد بیتهای استفاده شده برای بارگذاری مدل (مثلاً 16 بیت، 8 بیت، 4 بیت)
1.2 20٪ =افزونگی برای بارگذاری اضافی
پارامترهای مؤثر بر مصرف سختافزار:
اندازه مدل (پارامترها): مدلهای بزرگتر به حافظه و قدرت محاسباتی بیشتری نیاز دارند.
دقت: دقت پایینتر (مثلاً 8 بیت در مقابل 16 بیت) نیازهای حافظه را کاهش میدهد اما ممکن است بر عملکرد تأثیر بگذارد.
کمیتسازی: کاهش دقت پارامترهای مدل میتواند نیازهای حافظه و محاسباتی را به طور قابل توجهی کاهش دهد.
محاسبات توزیعشده: استفاده از چندین GPU میتواند به مدیریت محدودیتهای حافظه و بهبود عملکرد کمک کند.
مثال عملی:
تعداد پارامترهای مدل(Model parameters number): 10 میلیارد
دقت(Q): 16 بیت
کاربران همزمان (U): 100
زمان پاسخ:1 ثانیه
VRAM: \[ VRAM = \frac{10B \times 4B}{(32 / 16)} \times 1.2 = \frac{40}{2} \times 1.2 = 24GB \]
برای پردازش، GPUها مسئولیت اصلی را بر عهده دارند. با این حال، CPUها برای عملیات سیستم، مدیریت دادهها و وظایف پیش پردازش جزئی همچنان مورد نیاز هستند. هستههای CPU (برای عملیات سیستم): \[ Cores \approx \left(\frac{U}{T}\right) \times 0.1 = \left(\frac{100}{1}\right) \times 0.1 = 10 \]
RAM (برای مدیریت دادهها و وظایف پشتیبانی): \[ RAM \approx 64GB + (U \times 0.1GB) = 64GB + (100 \times 0.1GB) = 74GB \]
بنابراین، تمرکز اصلی بر روی داشتن VRAM کافی در GPUها برای پردازش مدل است، در حالی که CPUها و RAM از عملکرد کلی سیستم و مدیریت دادهها پشتیبانی میکنند.این تخمینها یک نقطه شروع فراهم میکنند، اما نیازهای واقعی میتواند بسته به معماری مدل و موارد استفاده خاص متفاوت باشد. ممکن است نیاز به تنظیمات بیشتری بر اساس آزمایش و بهینهسازی عملکرد باشد.
چگونه مدلهای زبانی بزرگ (LLMs) با رباتهای گفتگوی سنتی متفاوت هستند؟
مدلهای زبانی بزرگ (LLMs) مانند GPT-4 یا LLaMA سیستمهای پیشرفتهای هستند که بر روی مقادیر زیادی از دادههای متنی آموزش دیدهاند و به آنها توانایی درک و تولید متنی مشابه با زبان انسانی را میدهند. این مدلها در درک زبان پیچیده، تولید پاسخهای منسجم و تطبیق با موضوعات مختلف برتری دارند.
تفاوتهای کلیدی:
دادههای آموزشی: مدلهای زبانی بزرگ (LLMs): بر روی مجموعه دادههای عظیمی از منابع مختلف، از جمله کتابها، مقالات و وبسایتها آموزش دیدهاند. رباتهای گفتگوی سنتی: معمولاً بر روی مجموعه دادههای خاص مرتبط با کاربردشان آموزش دیدهاند.
درک زمینه:
مدلهای زبانی بزرگ (LLMs): میتوانند پاسخهایی مبتنی بر درک گسترده از زمینه تولید کنند.رباتهای گفتگوی سنتی: اغلب از اسکریپتهای از پیش تعریف شده پیروی میکنند و در درک زمینهای فراتر از برنامهریزیشان مشکل دارند.
انعطافپذیری:
مدلهای زبانی بزرگ (LLMs): میتوانند موضوعات مختلف و پرسشهای پیچیده را بدون برنامهریزی صریح برای هر سناریو مدیریت کنند.رباتهای گفتگوی سنتی: محدود به وظایف خاص و پاسخهای برنامهریزیشده، با انعطافپذیری کمتر در برخورد با پرسشهای غیرمنتظره هستند.
قابلیت تطبیقپذیری:
مدلهای زبانی بزرگ (LLMs): به طور مداوم از طریق تنظیم دقیق و بهروزرسانی دادههای آموزشی یاد میگیرند و بهبود مییابند. رباتهای گفتگوی سنتی: اغلب نیاز به بهروزرسانی دستی و برنامهریزی مجدد برای بهبود عملکرد یا مدیریت پرسشهای جدید دارند.



نقد و بررسیها
هنوز بررسیای ثبت نشده است.